Contributors to this chapter: Johan Miörner, Jonas Heiberg & Bernhard Truffer
This chapter introduces NVivo as the main tool for coding documents in STCA. In principle, any qualitative data analysis software that has the feature to export coded text fragments as a two-dimensional data matrix can be used. Researchers have successfully used both MaxQDA and AtlasTi, in addition to Nvivo. Future versions of the guide will map the differences between different coding software.
The chapter is divided into three parts. First, we present how to import source data in NVivo and what to consider when structuring folders and files. Second, we outline the basics of the coding structure in NVivo and how it relates to the different types of variables in the introductory chapter. Here we also present the basic terminology used in NVivo (see also the note on terminology). This is followed by an elaboration on different inductive, deductive and abductive coding approaches. Third, we present a practical introduction to the coding procedure. And finally, fourth, we instruct how to assign attributes to files.
NVivo allows you to code everything from single characters/words to entire (or even groups of) documents. Before starting your coding journey, it is worth reiterating how links in STCA are created through coding. If a text fragment is coded as two concept codes (both being mapped variables in the data structure) but without being simultaneously coded as an actor code (an associating variable), no association between the two concept codes will be established. For coded text to have meaning in STCA, it should thus always be coded with (at least) two codes: one associating variable (actor) and one mapped variable (concept). Keeping this in mind will help you better understand the different steps outlined below (see also the introduction).
Prerequisites: Installation of NVivo. For this guide, we have used the latest version of NVivo (14.23.2.46 as of April 2024). If your installation is older than March 2020 (version 12), there might be discrepancies with regard to some of the steps. However, in terms of functionality we have not observed any major differences.
Importing source data in NVivo
Different types of data can be imported in NVivo, ranging from text to movies, audio and images. With STCA, we are working mainly with text data, why this will be the focus of this section.
Text documents are represented by Files in NVivo. For example, if you work with newspaper articles, you would have each file contain a separate newspaper article. Similarly, if you are working with interview data, each file would contain a transcribed interview. Files can be assigned attributes, which essentially means that you are assigning attributes to individual text documents (e.g. the date of a newspaper article) that can later be used as portioning- or complementary variables. This will be described in detail under “Classifications and attributes” below. For this functionality to work, it is important that individual text documents (e.g. articles, interviews, project reports) are each imported as separate files in NVivo. For some applications, however, this is rather impractical and a better strategy from a performance point of view would be to have several independent text sources imported as one file (e.g. if you have a very large number of social media comments or similar). This guide does not cover this scenario. In short, it rules out the functionality of attributing individual files with information that can be used as partitioning- or complementary variables. This can instead be achieved by using codes for the same purpose. Future versions of the guide will elaborate more on this alternative approach.
A range of file formats are supported by NVivo (DOCX, TXT, XLSX, PDF, RTF, among others) and different data formats can be combined seamlessly in the same database. However, large numbers of PDFs in the same database should probably be avoided for performance reasons. If having the option to export e.g. newspaper articles in different file formats, it is a good idea to choose a format which supports basic formatting (e.g. DOCX or RTF) in order to increase readability during the coding procedure.
To import files to NVivo, click on Files under Data in the Quick Access column. You now have the option to click the Import tab and then click Files, or to simply drag and drop files to the main window.
Imported files can be organized in folders. New folders can be created by right-clicking on Files in the Quick Access column and clicking New Folder.
Imported files appear in the Files frame. To open a file, double click on it and it will open in a new tab to the right. If several files are open simultaneously, they appear as multiple tabs above the article.
Coding structure
Both Codes and Cases serve as simple containers of data material, in STCA most usually in the form of short snippets of text that have been assigned some form of categorical value based on a qualitative interpretation by the researcher.
In Nvivo, Codes serve as simple containers of data material. In STCA, this most usually takes the form of short snippets of text that have been assigned some form of categorical value based on a qualitative interpretation by the researcher. In STCA, we will use the core feature of NVivo to code text fragments as Codes. The process of assigning these values is referred to as coding. Both mapped and associating variables will be coded as Codes in NVivo.
Creating and organizing codes
To create a new code in your data structure, click on Codes in the Quick Access column, then right click on the open frame and click New Code. Give the code a name and click OK. It is now possible to assign data to the code you have just created.
Codes can be organized in hierarchical structures (tree structures) using parent- and child-codes. A code can simultaneously be a parent- and a child-code. It is also possible to aggregate all data from child-codes into parent-codes.
At the highest level (top-level parent codes), the coding structure can reflect the mapped and associating variables that you are using in your study. It is possible to select any group of codes for each mode in the matrix when doing the export, but to keep things organized it often makes sense to separate them while coding. In the examples here, we will use Actors as associating variable, and Concepts as the mapped variable. This means that a reasonable starting point is to create two top-level codes, namely Actors and Concepts.
To create child-codes, right click on the parent code and click New Code. You can also drag-and-drop codes between parent codes as you like.
A reasonable strategy is to start with only very broad categories of codes, since it is possible to re-organize and re-code existing material in NVivo also after doing initial rounds of coding.
Constructing a well-balanced, conceptually robust coding scheme
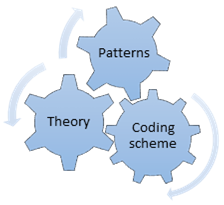
Achieving a well-balanced coding scheme is the key task of the coding activity in any qualitative research. A high quality coding scheme will consist of conceptually meaningful codes, which relate to key concepts in the theory applied and can be easily identified in empirical terms. The better the scheme fulfils these criteria, the easier and more robust the interpretation of the resulting maps and networks will be. Coding therefore represents one of the most decisive steps in conducting an STCA. Reflecting conventional epistemological approaches in the social sciences, the coding scheme can be constructed by relying on inductive, deductive or abductive (iterative) approaches.
In an inductive approach to coding, the researcher approaches the coding process without a set of codes defined by theory as point of departure. Instead, the coding is done in a bottom-up manner and search for patterns and potential categories that serve as a coding structure. For example, one might approach a set of newspaper articles reflecting a particular discourse by looking for any statements by actors on technologies or institutions and create codes reflecting the concepts appearing in the data, not anticipating particular concepts a priori. In other words, an inductive approach means that the coding tree is emergent from the coding process (Fig. 1).

In a deductive coding approach, the researcher derives a coding scheme based on theory at the beginning of the coding process. This means specifying the codes that are theoretically relevant and refrain from deviating from the pre-defined coding scheme during the coding process. For example, in a discursive approach to STCA, the researcher might be interested in categorising arguments for or against a pre-defined set of technologies. In such a research design, the coding scheme can be defined at the outset and remain unchanged throughout the coding process (Fig. 2).

However, most STCA applications to date have been based on an iterative abductive approach to coding, including a substantial element of trial-and-error. In an abductive approach, the researcher continuously iterates between data, emerging patterns and existing theory, to develop a coding scheme (Fig. 3). In such an approach, it is tremendously useful to do regular network visualizations, to receive feedback of the quality of the data and coding scheme early on, and adapt accordingly. A key ambition of STCA is to capture the core of the field with the chosen data sources and coding scheme. Comparing network visualizations with theoretical or empirical expectations may help you to know whether you should continue coding or adapt the choice of data sources or make changes to the coding scheme.
Finally, inter-coder reliability checks may be useful in order to check the consistency of the coding scheme if different parts of the dataset is coded by different researchers, or to ensure that the interpretation of key concepts is done in a coherent way. This is done simply by several researchers coding the same text, using the same coding approach, and comparing the results.
Aggregating data and working with different code-levels: towards a balanced scheme
By right-clicking on any code, you can select whether or not data coded as child-codes to this code should be coded also in the parent code (Aggregate Coding From Children). If this option is unselected, the parent code simply holds the child-code as a way for you to categorize codes in a tree-structure. If it is selected, then all information you code at all child-codes will also be coded in the parent-code. Furthermore, even if the Aggregate… option is disabled, you can code data at the level of a parent code.
To avoid confusion, an option is to only code data at the lowest level of codes in the tree structure. Coding data at different levels is however also possible, if being stringent about each level representing a consistent level of aggregation.
In many projects, the optimal code structure will emerge organically throughout the coding procedure (see below). A sound strategy is therefore to organize codes in a flat tree hierarchy, simply at the level of the associating and mapped variables (actors/concepts in our examples) during the first round of coding, and continue with developing different levels of aggregation in later rounds. Another common option is to start with an original, conceptually derived idea of a coding tree, which is revised through iterations between the emergent codes in a bottom-up manner.
During the coding process, you will notice how your intuition for different codes changes over time. Inductive categories may co-evolve with new theoretical or empirical insights. This will often lead to a desire to recode certain data, to develop new codes, split existing ones or merge two or several codes together. This is described in more detail below.
Keeping track of your progress and organizing files
NVivo does not give you a straightforward way to keep track of which files (e.g. newspaper articles) have been coded, read but deemed irrelevant, or are still to be coded. We have found two methods to deal with this:
If you do not need to keep irrelevant files in the database, you can simply sort the files by clicking on the References column when viewing the list of all your imported files. If the value is ‘0’, it means that nothing has been coded (and hence the file remains to be coded). All articles that are deemed irrelevant are then simply deleted.
However, you might want to keep “irrelevant” files in the database. The main reason for this is that it is sometimes hard to judge the relevance from the beginning and that you might want to be able to review them again at a later stage. In this situation, the easiest way is to create a folder structure for your files by right-clicking on the Files button under the Data tab in the Quick access bar to the left.
This allows you to organize your files in folders, for example based on whether they are coded or uncoded, or in any other way you deem relevant.
Coding procedure
In the examples that follow, we will assume that we are interested in coding actors as the associating variable and concepts as the mapped variable. Applications of STCA have also used other designs, such as scientific articles (associating variable) and topics (mapped variable). There is no need to a priori decide, which codes should be used as associating and mapped variables respectively, but this can be decided at the time of exporting the data from NVivo.
However, a key principle that must be observed when coding for STCA (in any software) is to code any text fragment by at least two codes. An association between two codes will appear in the network only if a text fragment is coded as both a mapped variable and an associating variable.
In the typical example of having actors (associating variable) and concepts (mapped variable) this means that a text fragment should be coded as at least one actor code (the actor who makes a statement or can be substantively linked to the content of the text, see below) and one concept code technology, institution, or other concept that is mentioned in the text). When deriving configurations from e.g. scientific articles or project documents (associating variables), text fragments can be coded as concepts (mapped variable), while the entire text document can be coded as, for example, the name of the article or document. Note that the introduction outlines several other combinations of possible mapped- and associating variables (and combinations), while the guide will describes the coding procedure for the general application of coding actors and concepts.
To code data at codes, we utilize the core functionality of NVivo in the way it was intended. Start by opening a file by double-clicking on one of the files you have imported in the previous step. This opens the file in a new tab.
After identifying a text fragment that fulfills the criteria for being coded according to your coding intuition and research design, there are several ways of coding it as a code in your data structure: you can select the text fragment and drag-and-drop it to pre-created codes in the list of Codes, or right-click on the selection and select Code selection (also Ctrl-F2). Coding can also be done using the coding bar at the bottom of the screen. All these alternatives will yield the same results.
To see everything (all text fragments) that have been coded at a particular code, you simply double-click on the code in question and it will open in a new tab. When looking at the content of a code, you can enable the Coding Stripes (top bar)to get information about what codes different text fragments have been coded at. These are enabled by clicking the Coding Stripes button and selecting All. The coding stripes appear on the right hand side and is (unfortunately) the only known way to see how text fragments have been coded.
Coding intuition: discursive and substantive approaches
Given the associating- and mapped variables we use in our examples (actors/concepts), we are looking for fragments of text that indicate an association of an actor to a concept. We are also often interested in how the concept is qualified. In general, we have distinguished between a discursive approach to coding, and a substantive approach.
With a discursive approach, one is interested in statements linking the “speaking” actor to a concept and how this link is qualified (for example by positive/negative or by a more detailed qualifier). A typical way to do this is to identify quotes by actors in newspaper articles, where an actor makes a statement about a concept of interest (typically a socio-technical element such as an institution, technology or another actor). For example, consider the following quote:
“Solar power is too expensive in a dark country like Sweden” says Lars Svensson, consultant at Dark Matter Inc. “Nuclear power is more affordable”
The most simple coding of this statement using a discursive approach involve identifying the associating variable (actor: Lars Svensson at Dark Matter Inc.) and the mapped variable (concepts: solar power; nuclear power). The actor also has a clear opinion about the two technologies: solar power is too expensive; nuclear power is affordable (qualifiers).
In this example, we would code the whole text fragment at three different codes:
- ‘Actor/Dark Matter Inc.’
- ‘Concept/Solar power – Too expensive’
- ‘Concept/Nuclear power – Affordable’
You can also consider coding information as a code representing the individual who made the statement on behalf of the organization, if this is more relevant than the organization in your research design. There is nothing that prevents you from coding the text fragment at two actor-codes simultaneously, i.e. coding it also at a code indicating the individual actor-level (e.g. ‘Individual/Lars Svensson’). It is important to keep in mind, however, that this means you have two actor codes which are not mutually exclusive, when you export the data (that is, it would most often not make sense to construct a network with overlapping individual- and organization-level actor-codes).
You might have noticed that there is information in the text fragment that is not coded in this example. The actor has an idea about the relationship between solar power and nuclear power (the latter is more affordable). He also refers to problems with solar power in a particular context (Sweden) and for a particular reason (it is dark). Whether this information is relevant, and thus whether it should be coded, depends completely on your research design. For the sake of simplicity, we do not take it into account in our example here.
With a substantive approach to STCA, an additional step of interpretation is added between the identification of text fragments and the coding at actor/concept-nodes. This includes both deriving associations based on other actors’ statements (as in the example below) or coding texts where activities of actors are reported. Take for example the following text fragment from an interview transcript with a representative of SunPower AG:
“We have had troubles selling our technology to Incredible Houses AG. When talking to our sales representatives, they keep complaining about the cost of solar power in relation to nuclear.”
In this example, it is not ‘Incredible Houses AG’ (actor) that says something about solar- and nuclear power (concepts), but we can still derive a link between the actors and these concepts based on the information in the text fragment.
The research design will determine how to make these interpretations, just as it would in a traditional study using interviews or other types of primary data. In some empirical settings, you might look to derive linkages between associating and mapped variables in your data structure based on simple interpretations of the content of the text fragment, as in the example. In other applications, however, you might add additional layers of interpretations, for example by relating certain statements or content to institutional logics or underlying rationales, or by connecting them to conceptual categories by using other qualitative methodologies.
Using the same coding structure as in the discursive example, we would thus code this text fragment as:
- ‘Actor/Incredible Houses AG’
- ‘Concept/Solar power – Too expensive’
- ‘Concept/Nuclear power – Affordable’
Just as when illustrating the discursive approach, you can see that there is information that is not coded in this example. We could for example derive a relationship between the two actors (SunPower AG and Incredible Houses AG). It also says something about the challenges facing the solar technology firm (troubles selling the technology to house builders). Whether or not you should code to capture this information depends, as with the previous example, on your research design.
Re-coding and combining codes
When you have familiarized yourself with the general coding procedure, you may start coding articles at a larger scale. You will probably notice how your feeling for the different codes tends to evolve over time, especially if you are using an inductive or abductive approach. Categories will continuously co-evolve with your theoretical knowledge and your knowledge about the subject matter.
For example, if you have started coding at a detailed level, codes may be partly overlapping or essentially contain the same kind of information. Relating to the examples in the previous section, it might be that you have one code ‘Concept/Solar power – Too expensive’ and another code ‘Concept/Solar power – Not affordable’. At a first instance, you may want to capture the nuance between the qualifiers ‘Not affordable’ or ‘Too expensive’ and thus code the text fragments as different codes. But in a second step, you might realize that this differentiation does not add any extra value to the analysis and thus want to group them together in one code. Or, correspondingly, it might be that you have initially coded all text fragments relating to the high cost of solar power into one main code and want to explore if there is nuance among the different positions of actors in relation to the high cost of solar power and therefore split this code into further sub-codes.
This will inevitably lead to the need to recode certain statements, to develop new codes, split existing ones or merge two codes.
Recoding text fragments to a new code can done by opening existing codes and code the text found in the ‘old’ code the same way you would code an original file. Double-click on a code to view its content and select the text fragment that should be recoded to a new node, and simply code it using the right-click menu or coding bar. The text fragment will now be coded at two codes simultaneously. If you want to uncode it from the current code (i.e. if you want to split one code into two or if you want to correct mistakes), you select the text fragment again and click uncode in the right-click menu or coding bar and select the codes from which you want to uncode the text fragment.
Combining codes so that all text fragments in Code A and Code B are coded at Code C can be done in two ways. One way is to recode all text fragments from Code A and B in a new Code C, by using the approach outlined in the previous paragraph. You can then simply remove Code A and B, or keep them with the remark that you now have Codes that are not mutually exclusive.
Another way is to create a new parent Code (Node C) and “Aggregate coding from children” in the code properties, and then move Code A and B to become sub-codes of Code C. In this way, Code C contains all statements coded at A and B and will continuously be updated with everything coded at these child-codes. This is very useful if you want to analyze your data at a higher/different level than was anticipated from the beginning.
The second approach gives you more flexibility when it comes to working with the data structure moving forward, but you have to be careful not to mix up the aggregated codes and the codes where you do the actual coding, since it will be possible to code individual statements also as Code C (meaning that they are coded as C but not at A or B). This is covered in more detail in the Coding Structure section.
Classification and attributes
NVivo allows you to assign attributes to files (text documents). This is done by creating lists of attributes connected to different types of codes or files, by using the classification function in NVivo.
This allows you to export subsets of your data based on a selection of files fulfilling certain criteria. For example, you can assign files (text documents) attributes indicating, for example, the name and location of the data source, or the date of publication. This is particularly relevant when working with newspaper data, since it allows you to export matrices corresponding to different time periods. Attributes can also be used to create more detailed descriptive statistics of your dataset (e.g. the number of articles in different time periods, and so on).
The data export procedure, network visualization and descriptive statistics are covered in other chapters of the guide. In the following, we will focus on how to assign attributes to text documents (files).
File-attributes are assigned through classification sheets that you can create on your own or based on pre-defined templates.
File classifications sheets are used if you want to be able to create networks representing only part of your source material. This has been useful for example when coding newspaper articles and we have wanted to show how a field has evolved over different time periods.
To create a new File classification sheet, click on File Classifications in the Quick Access menu. In the empty frame, right click and select New classification. Select if you want to base your classification sheet on a pre-existing template or if you want to create all attributes manually. To create attributes, right-click on the new file classification and select new attribute. Give the attribute a name and an appropriate data type.
For example, you can create a File classification sheet called ‘Newspaper Article’ with two attributes indicating the location and date of publication:
- Classification sheet: Actors
- Attribute 1: Actor type – Text
- Attribute 2: Location – Text
You will see that the new classification sheet now appears under File classification in the Quick Access menu. By clicking on it, you will see all items that have been classified in this category.
When having created a classification sheet, you can now classify files in your data structure. This is done by right-clicking on the corresponding file, click Classification and select the desired classification. This will add the item to the classification sheet. However, NVivo does not give you any further indication that this is done, which might be a bit confusing.
When a classification has been assigned to a file, the next step is to assign the relevant attributes that you created in the previous step. In our example, you want to assign the attributes “Location” and “Date” to a file, which you have classified as a Newspaper Article. The most straightforward way of doing this is to click the File classification button under the Home tab in the main menu, and under Open classification sheet select the appropriate one. This will open a sheet with the rows representing all items that have been classified and the columns representing attributes.
In our example, we open the Newspaper Article classification sheet, which lists all files that have been classified as Newspaper Articles, and for each file present in the sheet assign values for the Location and Date. How you decide to format these labels will vary depending on your research design. In order to avoid formatting problems later on and allow for easy computations in R, it does however make sense to use only standard characters and no spaces. For Date/Time it is possible to use the drop-down list to select the correct date, or write the date in the format that corresponds to your system settings (YYYY-MM-DD in most European language settings).