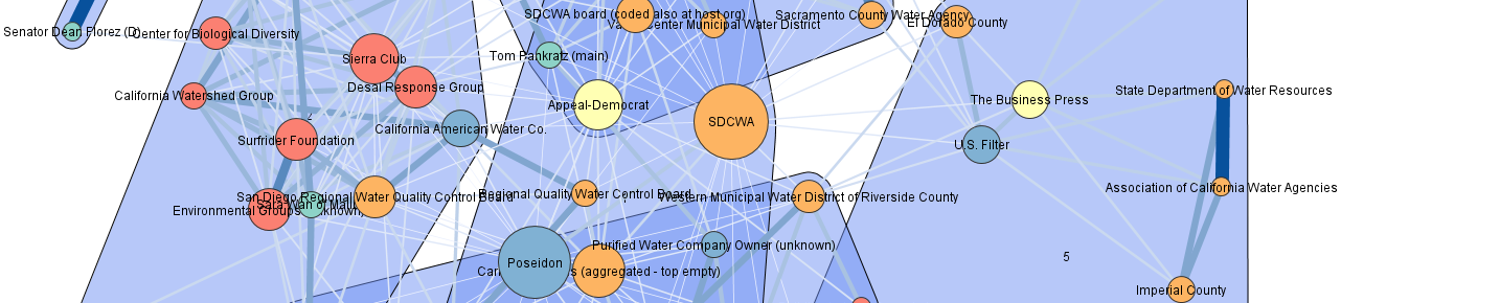
Contributors to this chapter: Johan Miörner, Jonas Heiberg & Bernhard Truffer
This chapter will outline how to export data from NVivo and how to apply filters based on, for example, attributes that have been assigned to files and codes. It also presents how to export attribute lists that can be used to improve network visualization and analysis in later steps.
Prerequisites: Installation of NVivo. For this guide, we have used the latest version of NVivo (14.23.2.46 as of April 2024). If your installation is older than March 2020 (version 12), there might be discrepancies with regards to some of the steps. However, in terms of functionality we have not observed any major differences.
Exporting data from NVivo
When you have finished coding the data, it is time to export a two-mode data matrix from NVivo, with rows and columns representing associated- and mapped variables. This is a key functionality of NVivo that allows us to use the software for STCA.
The export function will create a matrix with the mapped- and associating variables as rows and columns. For example, we might want to have Actors as rows and Concepts as columns, and the cells will contain information about the co-occurrence of coded statements at Actor-Concept combinations. Note that it does not matter for the analysis which type of variable is assigned to what axis in the matrix.
To illustrate, consider that you have a single file (text document) with a single text fragment which has been coded as ‘Actors/Eawag’ and ‘Concept/On-site sanitation’. Exporting this would render a matrix that looks like this:
| Concept/On-site sanitation | |
| Actors/Eawag | 1 |
In other words, you would have a co-occurrence matrix where Actors/Eawag and Concept/On-site sanitation have been co-coded a single time.
To export a two-mode data matrix, we use the Matrix Coding Query, which can be found under the Explore tab in the Main Menu of NVivo.
Step 1: select cells and rows
The first step is to select what codes you want to represent the rows and columns of your data matrix (i.e. your mapped- and associating variables). Here, it helps if you have followed our recommendation to distinguish between the different types of variables through top-level codes in your code tree (see Chapter 3), but in principle you are free to select any codes in your data structure as both rows and cells.
For our example here, we assume that you want to put the associating variable (in this case Actors) as rows.
Begin by clicking on the + symbol under the Rows box, and click Select items…. You also have the possibility to select codes based on their attribute values, according to the same logic as for other filtering purposes (see below), but for our example we will use a manual selection of codes for the associating variable.
In the dialogue box that appears, you have the possibility to select any data in NVivo. Following the coding procedure described in Chapter 3, we want to select Cases, as they represent codes in our data structure. To select all Cases under the ‘Actor’ top-level code (our associating variable in this example), you can check the box Automatically select descendant codes and then click on the Actor code. This will select all Actor-codes in our data structure.
Bear in mind, however, that if you have followed the recommendations in Chapter 3, the top-level code is either empty, or an aggregation of all child-codes, and as such not relevant for our analysis. Therefore, do not forget to deselect all codes that are not directly representing actors (e.g. top-level container codes, temporary recoded codes, etc.). To be able to deselect the top-level code without deselecting all the child-codes, you will again need to uncheck Automatically select descendant codes.
Before clicking OK, it is possible to use the Filter function also when selecting codes in this dialogue box. More on that below.
All codes that will appear as rows in your data structure should now be listed in the box. The next step is to repeat the procedure for the columns on the right-hand side, selecting your mapped variables.
Step 2: select data sources
The second step is to select the text documents (files) you want to be included in your export. Only co-occurrences found in the selected files will be reflected in the exported matrix.
There may be several reasons for why you want to include only a subset of your complete dataset in any given export. One that has been mentioned previously is that you might want to divide the data into time periods, based on for example the publication date of newspaper articles, company reports or any other dated material. Or you might want to create networks based on a subset of interview partners or other data sources, for any practical reason.
If you want to include all files, simply leave the option Search in: Files and externals enabled. If you want to select files manually, click Select Items… and select all files that you want to include. This is a fairly straightforward process and you can also choose to select folders, for example if you have sorted your source data according to relevant categories (or time periods).
Step 3: Run the query and save the export
The third step is to click Run query and wait for what seems like an unreasonable amount of time. The resulting matrix will eventually appear as a table in the bottom part of the window.
Before saving the export, you will probably want to remove the row- and column ID-numbers that are added by NVivo (in order to make labelling the nodes in Visone more straightforward). This is done by right-clicking anywhere on the table, and de-select Row- and Column IDs respectively.
In addition you might want to consider if you want the numbers in each cell to represent the number of files (text documents) in which a concept-actor link is established or the absolute number of co-occurrences.
By default, the matrix coding query will provide you with the absolute number of co-occurrences coded in your dataset. This may provide valuable information, but may also distort your results, depending on your research design. Take for example the coding of newspaper articles: if the same actor makes different statements about the same concept in the same article, each of these will count as a co-occurrence with the default export settings. This will most likely distort the results. Sometimes it is more relevant in how many files (i.e. text documents such as individual newspaper articles) an actor-concept combination has been coded. To mitigate this, NVivo offers the possibility to only count one co-occurrence per text document. This is done after running the query by clicking Files coded – All classifications under the Matrix tab in the Main menu.
Note, however, that if the desired output is an unweighted two-mode network, both the ‘absolute number of co-occurrences’ and the ‘in how many files’ options will be converted into a binary (1/0) relationship for each actor-concept combination when doing network transformations in the next step.
The final step in NVivo is to right-click anywhere on the table and select Export Coding Matrix… and save the excel-file on your computer. In order to enable computation in R and visualization in Visone, you need to convert the output-file to the CSV format. This is done by opening the file in excel, click save-as and select CSV (Comma delimited) as the output format. Excel will tell you that some formatting will be lost but this is not an issue. Name and save the output file – this is the file that we will work with in the next sections and chapters.
Introduction to filtering
NVivo offers the possibility of applying filters at several of the steps outlined above. The filtering functionality can thus be applied in a variety of ways, much of which is beyond the scope to cover here.
Two applications of the filtering function have however proved particularly valuable for the STCA methodology.
- Filter text documents (files) based on partitioning variables, such as date of publication (of newspaper articles). This allows for creating separate networks for different time periods, for example if working with newspaper data.
- Filter the association- and mapped variables based on complementary variables (attributes assigned through classifications). For example, you might want to create a network visualizing concept congruence only among a subset of actors (filter on actor-type and include all concepts).
We will illustrate these two applications here, but there are of course many other. Note that NVivo allows for multi-layered filtering (you can filter the content of the filters you create). This might be useful, but also terribly confusing.
Filter text documents based on date range
In order to filter text document (files) based on date information, you must first have classified the files and assigned date values as attributes (see Chapter 3).
The filtering takes place at the step before running the Matrix Coding Query. Instead of including all files, or manually selecting files, you will select files based on a set of criteria that you define.
Click Search in – Selected Items…, do not select any items in the dialogue that appears (and make sure that the selection is empty) but click Filter in the bottom left corner. In the filtering-dialogue, you can filter files based on simple selection criteria (you can explore this as you wish, it is sometimes enough), but we will use the advanced filtering function.
This allows us to add a set of interacting criteria, just as a simple (but limited) SQL-query. To filter on a date range, we will add one criteria for the start date and one criteria for the end date. This is done by adding the following criteria to the list:
| Interaction: Attribute. Click select and choose the date attribute of your file classification sheet. | Option: >= value. | Value: Start date |
| Interaction: Attribute. Click select and choose the date attribute of your file classification sheet. | Option: <= value. | Value: End date |
Remember to click Add to list after setting each criteria. They should appear in the list. Finally, click Find now. You will now return to the file selection dialogue box and should see that some files have been selected but not others. If everything worked as expected, only files with the date attribute within your range will be selected. When running the query with the filter activated, the output will only include files fulfilling the criteria set in the filter.
Filter content of rows/cells
In addition to filter data sources, you can create filters for identifying which codes to include in the rows and columns of your data matrix. This is done at the step where you select items for the rows- and columns respectively (click the + symbol – Select items…).
The procedure is identical to the one described in the previous section. If you want to filter out codes based on a simple criteria (such as only one actor type), you can use the simple filtering function. You can also add several criteria by using the advanced function.
Export attribute lists
NVivo allows you to export the classification sheets as attribute lists. These can be incredibly useful when visualising your data in Visone, as well as a basis for descriptive statistics.
However, in order to make use of this functionality, it is important that you have developed a structured way of classifying codes and files, and have assigned attributes coherently across different codes (see Chapter 3).
To export an attribute list you simply select the classification sheet you want to export by navigating to it in the Quick Access Bar, right-click – Export – Export classification sheet. In the dialogue that appears, you can make some settings with regard to missing values and date formats. The default options usually work well. Save the file anywhere on your computer and convert it to CSV by re-saving it in Excel.
How to utilize the information in these attribute lists when visualizing the network is described in Chapter 6.
Preparing additional attribute files
In addition to information about the codes found in the classification sheets, you might want to prepare additional attributes (e.g. to serve as complementary variables in your STCA plots) that can be used to better visualize the networks. For example, you might want to know how many links an actor has to other actors in the network and change the size of the network nodes accordingly. Or similarly, the number of times a concept has been co-framed with other concepts may be relevant.
This information is not directly available from NVivo, but it easy to calculate when you have exported the data matrix to excel where you can simply calculate the sum of rows and columns.
For example, you may have exported the following two-mode matrix (see Fig. 1) from NVivo. [1] The matrix consists of three Actors (1-3, columns) and three Concepts (1-3, rows). By calculating the row sums, you can reveal that Concept 1 has been referred to five times, Concept 2 four times and Concept 3 one time. If you want to know the number of actors that have referred to a particular concept (regardless of how many times, that is, in how many different documents, they have referred to it), you can count the number of cells in a row that contains a value over 0 by using the excel formula =COUNTIF(range;”>0″). In the example below, Concept 1 has been used by two actors, Concept 2 by three actors and Concept 3 by one actor.
Correspondingly, the column sums represents how many times (in different text documents, i.e. files) an actor is linked to concepts in the data, that is, how present they are in the dataset. In the example below, Actor 1 has referred to concept 1 one time and concept 2 two times, totalling three links to concepts. Actor 2 only appear once and Actor 3 appears six times. As with concepts, we can also count the number of cells that contain a value higher than 0 to know the number of concepts a particular actor has used. In the example, Actor 1 has used two different concepts, Actor 2 has used one concept and Actor 3 has used three concepts. This information can be used as descriptive statistics, indicating the prevalence of certain concepts in the field, or to inform the size or colours of nodes when visualizing the network in Visone.
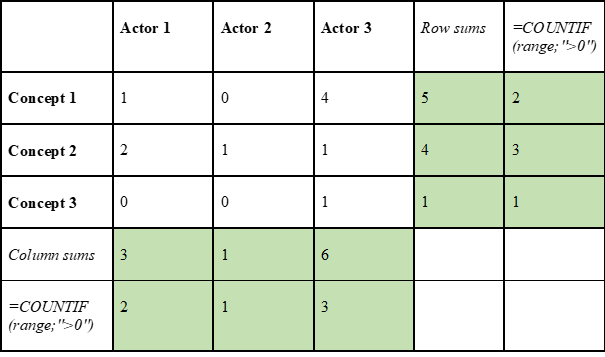
Correspondingly, you can calculate row or column sums for one-mode matrices (the sums will be the same for both axes). The row/column sums for a one-mode actor-matrix refer to the number of links each actor has to other actors in the network. And row/column sums for a one-mode concept-matrix refer to the number links a concept has to other concepts. For normalized data, the excel formula =COUNTIF(range;”>0″) needs to be used.
Creating attributes “by hand” (in Excel)
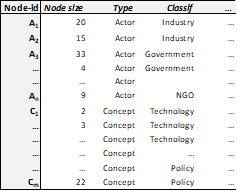
Depending on the specific dataset and research question, you might find it more convenient to creata attribute files by hand, i.e. type in the relevant data in a separate excel file. For an attribute file, you need to list the first column with the names of codes (concepts and actors) that are identical to the headers in your exported data matrix (see section 4). In general, it makes sense to construct one attribute file that includes concept and actor attributes. Visone will match the values depending on the relevant identifier (see Table 1). However, you may also create separate files for concepts and actors if you find this more tidy.
You will then typically have one column indicating the “size” of the node in terms of number of times coded or similar measures. Other typical attribute values refer to higher classes of concepts (e.g. overarching themes) or actors (e.g. actor types). It also makes sense to add a column identifying concepts and actors, in case you want to draw two-mode networks and distinguish the two types of codes by different shapes. You may add whatever further attributes as additional columns to your attribute excel file, depending on what information you want to depict in terms of size, fill color, line color, label color, or shape of your nodes. In particular, you might want to include network statistics like degree centrality, or in beteenness centrality in your attribute list. To gain these, you might have to run the corresponding procedure in Visone first and then copy the values (or rather export them from Visone) as additional columns.
In some cases you might even want to create attributes for the edges in order to differentiate them in terms of color, line type and thickness. For that you have to create an excel sheet with a first column of numbers ranging from 1 to n*(n-1)/2 (assuming that n is the number of nodes in your one-mode network, see table 2). The logic of numbering edges follows the following pattern:
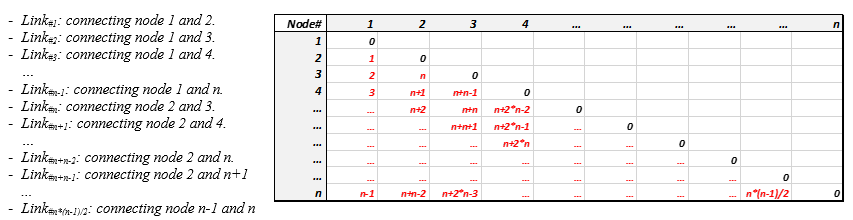
The attribute file might then look like the one depicted in Table 3:
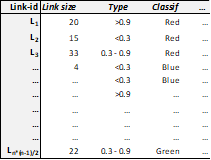
Once you have finished composing the attribute file(s) you may save them in .CSV format, under an appropriate filename and then it will be ready for import in Visone to shape your nodes and links appropriately.
[1] Note that the choice made with regard to counting the absolute number of co-occurrences or the number of files in which an actor has been linked to a concept will have a big impact on how to interpret the row and column sums (see Step 3 under Exporting data to NVivo above).
Some additional steps and details are necessary to consider when you want to use data attributes in Visone by importing classification sheets made in NVivo.
1. First, it is important to ensure that the row and column IDs are unchecked when exporting your matrix from NVivo. This way, the IDs of the nodes in your Visone network will correspond to the names of the actors/concepts in your classification sheet.
2. When exporting your classification sheet from NVivo, make sure that the “Item name format” setting is set to “Name”.
3. Import the classification sheet in Visone in the “import & export” section in the attribute manager. The attribute manager can be accessed by clicking the blue rectangle with gold lines, located in the toolbar at the top of the program. Locate the file by clicking the button with three dots in the ‘import’ section, and click import.
4. In the import menu, ensure that the network attribute is set to ‘id’ and the file attribute is set to the name of your classification sheet. Click ‘ok’. This should join the attributes to your network nodes and enable you to map them.